Проект: Прогнозирование температуры звезды¶
Описание проекта:
Обычно для расчёта температуры звезды учёные пользуются следующими методами:
- Закон смещения Вина.
- Закон Стефана-Больцмана.
- Спектральный анализ.
Каждый из них имеет плюсы и минусы. Обсерватория хочет внедрить технологии машинного обучения для предсказания температуры звёзд, надеясь, что этот метод будет наиболее точным и удобным. В базе обсерватории есть характеристики уже изученных 240 звёзд.
Цель проекта: Найти решение задачи регрессии по определению температуры на поверхности обнаруженных звёзд с помощью нейросети и точностью прогноза RMSE <= 4500.
Описание данных:
6_class.csv — описание уже изученных звезд.
Описание признаков:
Luminosity(L/Lo)— светимость звезды относительно Солнца;Radius(R/Ro)— радиус звезды относительно радиуса Солнца;Absolute magnitude(Mv)— абсолютная звёздная величина, физическая величина, характеризующая блеск звезды;Star color— (white,red,blue,yellow,yellow-orangeи др.) — цвет звезды, который определяют на основе спектрального анализа;Star type— тип звезды (описание типов в таблице ниже);
| Тип звезды | Номер, соответствующий типу |
|---|---|
| Коричневый карлик | 0 |
| Красный карлик | 1 |
| Белый карлик | 2 |
| Звёзды главной последовательности | 3 |
| Сверхгигант | 4 |
| Гипергигант | 5 |
Temperature (K)—(Целевой признак)— абсолютная температура на поверхности звезды в Кельвинах.
Ход исследования:
Подготовка данных: загрузка и изучение общей информации из представленных датасетов.Предобработка данных: стандартизация данных и обработка явных и неявных дубликатов.Исследовательский анализ данных: изучение признаков имеющихся в датасетах, их распределение, поиск выбросов/аномалий в данных.Корреляционный анализ: изучение взимосвязей между входными признаками и целевыми, а также и между ними.Подготовка данных к обучению модели: деление данных на тестовую и тренировочную выборки, feature engineering, отбор признаков для обучения с помощьюmutual_info_regression, построение пайплайна обработки данных.Построение базовой нейронной сети: получение бызовой метрики по тестовой выборки с помощью закона Стефана-Больцмана, построение базовой нейронной сети, где определяется архитектура модели и получение метрики качества ее прогноза на тестовой выборке и анализ результатов.Улучшение нейронной сети: подбор гиперпараметров для ранее полученной нейросети, добавление регуляризации и обучения с помощью батчей, получение метрики качества ее прогноза на тестовой выборке и анализ результатов, тестируется добавление аугментированных данных для улучшения точности прогноза нейросети.Общий вывод: резюмирование полученных результатов, формулировка ключевых выводов.
Подготовка рабочей среды и вспомогательные функции¶
Импорт библиотек и базовые настройки блокнота:¶
# Стандартные библиотеки
import math
import random
# Сторонние библиотеки
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import phik
import scipy.stats as stats
import seaborn as sns
from IPython.display import display
from scipy.stats import anderson
from statsmodels.stats.outliers_influence import variance_inflation_factor
from sklearn.compose import ColumnTransformer
from sklearn.decomposition import FastICA
from sklearn.feature_selection import mutual_info_regression
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import (OneHotEncoder,
StandardScaler,
FunctionTransformer)
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, TensorDataset
# Базовые настройки блокнота
sns.set()
sns.set_context('paper')
pd.set_option('display.max_column', None)
pd.set_option('display.max_colwidth', None)
# Фиксируем случайность для воспроизводимости результатов
RANDOM_STATE = 6011994
random.seed(RANDOM_STATE)
np.random.seed(RANDOM_STATE)
torch.manual_seed(RANDOM_STATE)
torch.use_deterministic_algorithms(True)
Вспомогательные функции:¶
# Функция для получения общей информации о датафрейме
def gen_info(df):
'''
Данная функция выводит общую информацию
о датафрейме, статистическое описание признаков
и 5 рандомных строк.
На ввод функция принимает переменную датафрейма.
'''
# Статистики по количественным признакам
desc = df.describe().T
# Вывод результатов
print(df.info())
display(desc)
display(df.sample(5, random_state=RANDOM_STATE))
# Функция для поиска неявных дубликатов
def hidden_dup_search(df):
'''
Данная функция приводит значения категориальных
столбцов к единому стилю и выводит их уникальные
значения.
На ввод функция принимает переменную датафрейма.
'''
# Список категориальных признаков
df_cat_col = df.select_dtypes(include = 'object').columns.tolist()
# Приводим все значения к единому стилю
# и проверяем уникальные значения для
# точечной проработки при необходимости
for feature in df_cat_col:
df[feature] = df[feature].str.lower().str.replace(' ', '_').str.replace('-', '_')
print(f'Уникальные значения признака: {str(feature)}')
print(df[feature].unique())
print()
# Функция для комплексного анализа количественного признака
def analyzis_quantity(df, x_label, y_label='Частота', target=None,
hue=None, size=None, sizes=None, system=False,
discrete=False, log_scale=False, title_hist=None,
title_scatter=None):
'''
Данная функция выводит "коробочный" график и гистограмму
по указанному столбцу датафрейма и его статистические метрики.
Аргументы функции:
df - данные (pd.Series)
x_label - подпись для оси Х
y_label - подпись для оси Y (по умолчанию "Частота")
target - целевая переменная для scatter-графика (если system=True)
hue - переменная для цветового кодирования (если system=True)
size - переменная кодирования по размеру (если system=True)
sizes - переменная для уточнения диапозона кодировки размеров (если system=True)
system - флаг для построения scatter-графика
discrete - булевое значение, дискретные значение или нет.
log_scale - логарифмическая шкала для гистограммы
title_hist - заголовок для гистограммы и boxplot
title_scatter - заголовок для scatter-графика
'''
# Названия для графиков по умолчанию
if title_hist is None:
title_hist = f"Распределение {df.name if hasattr(df, 'name') else 'входной признак'}"
if title_scatter is None:
target_name = target.name if hasattr(target, 'name') else 'таргета'
feature_name = df.name if hasattr(df, 'name') else 'входной признак'
title_scatter = f"Зависимость {target_name} от {feature_name}"
# Создание составного графика: boxplot + histogram
fig, (ax_box, ax_hist) = plt.subplots(2, sharex=True,
figsize=(8, 5.6),
gridspec_kw={'height_ratios': (.15, .85)})
# Boxplot
sns.boxplot(x=df, orient='h', ax=ax_box)
ax_box.set(xlabel='')
# Histogram
n_bins = round(1 + math.log2(len(df))) if len(df) > 1 else 10
sns.histplot(x=df, bins=n_bins, discrete=discrete, log_scale=log_scale, ax=ax_hist)
# Общие настройки для основной фигуры
ax_hist.set_xlabel(x_label, fontsize=10)
ax_hist.set_ylabel(y_label, fontsize=10)
ax_hist.tick_params(axis='both', which='major', labelsize=10)
fig.suptitle(title_hist, fontsize=12, fontweight='bold', y=0.95)
# Настройка тиков для дискретных значений
if discrete == 'unique':
unique_vals = np.sort(df.dropna().unique())
ax_hist.set_xticks(unique_vals)
elif discrete == 'non_unique':
ax_hist.set_xticks(np.arange(df.min(), df.max() + 1, 1))
# Отображение первой фигуры
fig.tight_layout()
# Scatter plot (если запрошено)
if system:
if hue is not None:
fig_2, ax_2 = plt.subplots(figsize=(10, 5.34))
else:
fig_2, ax_2 = plt.subplots(figsize=(8, 5.34))
sns.scatterplot(x=df, y=target, alpha=0.5, hue=hue, size=size, sizes=sizes, ax=ax_2)
fig_2.suptitle(title_scatter, fontsize=12, fontweight='bold', y=0.95)
ax_2.set_xlabel(x_label, fontsize=10)
ax_2.set_ylabel(target.name if hasattr(target, 'name') else 'Целевая переменная', fontsize=10)
ax_2.tick_params(axis='both', which='major', labelsize=10)
if hue is not None:
ax_2.legend(bbox_to_anchor=(1.025, 1), loc='upper left', fontsize=10)
fig_2.tight_layout()
if log_scale:
plt.xscale('log')
plt.yscale('log')
# Отображение графика
plt.show()
# Вывод статистических метрик
display(df.describe().to_frame().T)
# Проверяем нормальность распределения
result = anderson(df.dropna())
if result.statistic < result.critical_values[2]:
distr = 'Нормальное'
else:
distr = 'Не является нормальным'
test_anderson = {'':['Статистика:',
"Критические значения:",
'Распределение'],
'Тест на нормальность распределения (порог=0.05):': [result.statistic,
result.critical_values,
distr]
}
display(pd.DataFrame(test_anderson).set_index(''))
# Функция для анализа категорийных значений
def analyzis_category(df, title=None, kind='bar'):
'''
Данная функция выводит столбчатый график
по указанному столбцу датафрейма и его значения
в табличном виде.
Аргументы функции:
df - данные
name - название графика
kind - ориентация графика вертикальная или
горизонтальная, принимает значения "bar" и "barh".
'''
# Название для графика по умолчанию
if title is None:
title = f"Соотношение категорий {df.name if hasattr(df, 'name') else 'входного признака'}"
# Подсчитываем количество каждого значения
category_count = df.value_counts(ascending=True)
# Создание столбчатого графика
plot_bar = category_count.plot(kind=kind, figsize=(8, 5.6), grid=True)
# Настройка заголовка и подписей
if kind == 'bar':
plt.title(title, fontweight='bold', fontsize=12)
plt.xlabel('')
plt.ylabel('Частота', fontsize=10)
plt.tick_params(axis='both', which='major', labelsize=10)
plt.xticks(rotation=0)
else:
plt.title(title, fontweight='bold', fontsize=12)
plt.xlabel('Частота', fontsize=10)
plt.ylabel('')
plt.tick_params(axis='both', which='major', labelsize=10)
plt.xticks(rotation=0)
# Отображаем график
plt.tight_layout()
plt.show()
# Вывод значений в табличном виде
display(pd.DataFrame(category_count).reset_index())
# Построение таблицы с расчитанным VIF
def vif_factor(data, columns):
'''
Данная функция расчитываем VIF-фактор
для количественных признаков датафрейма.
На ввод функция принимает:
data - датафрейм
columns - список количественных признаков.
'''
vif_data = pd.DataFrame()
vif_data['input attribute'] = columns
vif_data['vif'] = ([variance_inflation_factor(data[columns].values, i)
for i in range(data[columns].shape[1])])
return vif_data
# Функция для подготовки данных к обучению модели
def add_feature(X):
X = X.copy()
X['log_luminosity'] = np.log(X['luminosity'])
X['log_radius'] = np.log(X['radius'])
X['ica_abs_magnitude'] = X['abs_magnitude']
return X
# Функция для расчета эффективной температуры с помощью закона Стефана–Больцмана
def baseline_bf(X, y):
L_0 = 3.828 * 10**26
R_0 = 6.9551 * 10**8
sigma = 5.67 * 10**(-8)
X = X.copy()
T = ((X['luminosity'] * L_0) / (4 * np.pi * (X['radius'] * R_0)**2 * sigma))**(0.25)
rmse_score = np.sqrt(mean_squared_error(y, T))
print(f'Значение метрики RMSE: {rmse_score:.3f}')
return rmse_score
# Функция построения графика для анализа результатов прогноза
def analyzis_test(y_true, y_pred):
# Объединение данных в один датафрейм
y_pred = pd.Series(y_pred, index=y_true.index, name='pred')
df = pd.concat([y_true.rename('true'), y_pred], axis=1)\
.reset_index()
# Длинный формат таблицы
df = df.melt(id_vars='index',
var_name='type',
value_name='temperature')
# Построение графика
plt.figure(figsize=(15, 5.6))
sns.barplot(data=df,
x='index',
y='temperature',
hue='type')
# Настройка заголовка и подписей
plt.title('Анализ прогноза модели', fontweight='bold', fontsize=12)
plt.xlabel('Номер звезды в данных', fontsize=10)
plt.ylabel('Температура звезды', fontsize=10)
# Вывод графика
plt.tight_layout()
plt.show()
# Функция для установление весов по умолчанию
def init_weights(layer):
if isinstance(layer, nn.Linear):
nn.init.xavier_uniform_(layer.weight)
if layer.bias is not None:
nn.init.zeros_(layer.bias)
Общая информация о данных¶
Загрузка данных:¶
# Загрузка данных
df = pd.read_csv('../data/6_class.csv', index_col=0)
Общая информация о датафрейме:¶
Описание данных:
6_class.csv — описание уже изученных звезд.
Описание признаков:
Luminosity(L/Lo)— светимость звезды относительно Солнца;Radius(R/Ro)— радиус звезды относительно радиуса Солнца;Absolute magnitude(Mv)— абсолютная звёздная величина, физическая величина, характеризующая блеск звезды;Star color— (white,red,blue,yellow,yellow-orangeи др.) — цвет звезды, который определяют на основе спектрального анализа;Star type— тип звезды (описание типов в таблице ниже);
| Тип звезды | Номер, соответствующий типу |
|---|---|
| Коричневый карлик | 0 |
| Красный карлик | 1 |
| Белый карлик | 2 |
| Звёзды главной последовательности | 3 |
| Сверхгигант | 4 |
| Гипергигант | 5 |
Temperature (K)—(Целевой признак)— абсолютная температура на поверхности звезды в Кельвинах.
gen_info(df)
<class 'pandas.core.frame.DataFrame'> Index: 240 entries, 0 to 239 Data columns (total 6 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Temperature (K) 240 non-null int64 1 Luminosity(L/Lo) 240 non-null float64 2 Radius(R/Ro) 240 non-null float64 3 Absolute magnitude(Mv) 240 non-null float64 4 Star type 240 non-null int64 5 Star color 240 non-null object dtypes: float64(3), int64(2), object(1) memory usage: 13.1+ KB None
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| Temperature (K) | 240.0 | 10497.462500 | 9552.425037 | 1939.00000 | 3344.250000 | 5776.0000 | 15055.5000 | 40000.00 |
| Luminosity(L/Lo) | 240.0 | 107188.361635 | 179432.244940 | 0.00008 | 0.000865 | 0.0705 | 198050.0000 | 849420.00 |
| Radius(R/Ro) | 240.0 | 237.157781 | 517.155763 | 0.00840 | 0.102750 | 0.7625 | 42.7500 | 1948.50 |
| Absolute magnitude(Mv) | 240.0 | 4.382396 | 10.532512 | -11.92000 | -6.232500 | 8.3130 | 13.6975 | 20.06 |
| Star type | 240.0 | 2.500000 | 1.711394 | 0.00000 | 1.000000 | 2.5000 | 4.0000 | 5.00 |
| Temperature (K) | Luminosity(L/Lo) | Radius(R/Ro) | Absolute magnitude(Mv) | Star type | Star color | |
|---|---|---|---|---|---|---|
| 150 | 29560 | 188000.00000 | 6.0200 | -4.01 | 3 | Blue-white |
| 127 | 2861 | 0.00019 | 0.0899 | 16.71 | 0 | Red |
| 191 | 3257 | 0.00240 | 0.4600 | 10.73 | 1 | Red |
| 28 | 11790 | 0.00015 | 0.0110 | 12.59 | 2 | Yellowish White |
| 165 | 7282 | 131000.00000 | 24.0000 | -7.22 | 4 | Blue |
Вывод:¶
Получив общую информацию о датафрейме, можем сделать следующие выводы и построить предварительный план по предобработке данных:
- Нужно поменять названия столбцов для удобства работы;
- Пропуски отсутствуют;
- Типы данных корректны;
- Необходимо проверить данные на явные и неявные дубликаты.
Предобработка данных¶
Переименование названия столбцов:¶
df = df.rename(columns={'Temperature (K)': 'temperature',
'Luminosity(L/Lo)': 'luminosity',
'Radius(R/Ro)': 'radius',
'Absolute magnitude(Mv)': 'abs_magnitude',
'Star type': 'star_type',
'Star color': 'star_color'})
Неявные дубликаты:¶
hidden_dup_search(df)
Уникальные значения признака: star_color ['red' 'blue_white' 'white' 'yellowish_white' 'pale_yellow_orange' 'blue' 'whitish' 'yellow_white' 'orange' 'white_yellow' 'blue_' 'yellowish' 'orange_red' 'blue_white_']
Мы получили 14 уникальных значений, когда звезды по цвету и температуре делят на 7 категорий:
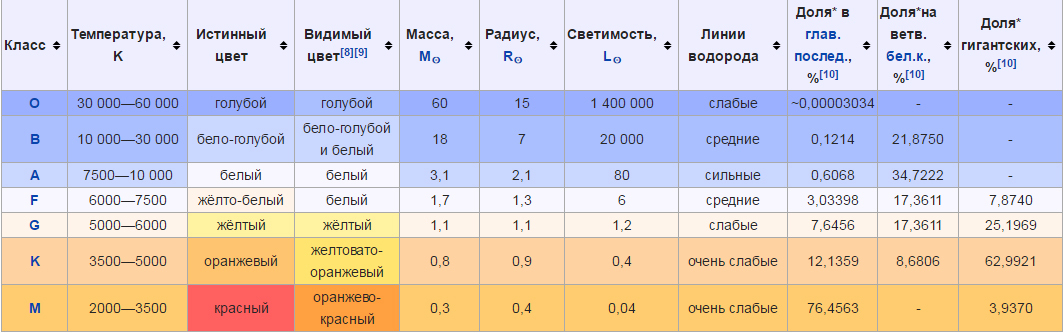
Цвета звезд были получены на основе спектрального анализа, скорректируем названия согласно им.
# Фильтрация по неоднозначным цветам звезд
df[df['star_color'].isin(['whitish', 'yellowish', 'orange_red', 'pale_yellow_orange'])]
| temperature | luminosity | radius | abs_magnitude | star_type | star_color | |
|---|---|---|---|---|---|---|
| 29 | 7230 | 0.00008 | 0.013 | 14.080 | 2 | pale_yellow_orange |
| 33 | 9700 | 74.00000 | 2.890 | 0.160 | 3 | whitish |
| 35 | 8052 | 8.70000 | 1.800 | 2.420 | 3 | whitish |
| 91 | 4526 | 0.15300 | 0.865 | 6.506 | 3 | yellowish |
| 92 | 4077 | 0.08500 | 0.795 | 6.228 | 3 | yellowish |
| 93 | 4980 | 0.35700 | 1.130 | 4.780 | 3 | yellowish |
| 96 | 5112 | 0.63000 | 0.876 | 4.680 | 3 | orange_red |
Судя по всему эти названия видимых цветов звезд, заменим их соответствующий им истинный.
pale_yellow_orange— определяем, как оранжевый цвет;whitish— определили, как белый;yellowish— определили, как желтый;orange_red— определили, как красный.
# Карта замены значений
mapping = {'yellowish_white': 'yellow_white',
'pale_yellow_orange': 'orange',
'whitish': 'white',
'white_yellow': 'yellow_white',
'blue_': 'blue',
'yellowish': 'yellow',
'orange_red': 'red',
'blue_white_': 'blue_white'}
# Замена значений
df['star_color'] = df['star_color'].replace(mapping)
# Проверка замены
print(f'Кол-во уникальных значений: {df["star_color"].nunique()}')
print(f'Уникальные значения: {df["star_color"].unique().tolist()}')
Кол-во уникальных значений: 7 Уникальные значения: ['red', 'blue_white', 'white', 'yellow_white', 'orange', 'blue', 'yellow']
Теперь наши значения приведены к стандарту и избавлены от неявных дубликатов.
Явные дубликаты:¶
# Количество явных дубликатов
df.duplicated().sum()
np.int64(0)
Явные дубликаты отсутствуют.
Выводы:¶
- Названия колонок приведены к
snakeвиду; - Исправлены неявные дубликаты в признаке
star_color; - Явные дубликаты отсутствуют.
Исследовательский анализ¶
Количественные признаки:¶
# Список количественных признаков
num_col = ['temperature',
'luminosity',
'radius',
'abs_magnitude']
# Статистическое описание количественных признаков
df[num_col].describe().T
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| temperature | 240.0 | 10497.462500 | 9552.425037 | 1939.00000 | 3344.250000 | 5776.0000 | 15055.5000 | 40000.00 |
| luminosity | 240.0 | 107188.361635 | 179432.244940 | 0.00008 | 0.000865 | 0.0705 | 198050.0000 | 849420.00 |
| radius | 240.0 | 237.157781 | 517.155763 | 0.00840 | 0.102750 | 0.7625 | 42.7500 | 1948.50 |
| abs_magnitude | 240.0 | 4.382396 | 10.532512 | -11.92000 | -6.232500 | 8.3130 | 13.6975 | 20.06 |
По статистие количественных признаков можем видеть, что у первых 3х признаков положительно скошенное распределение. Аномалий в значениях не наблюдаем. Рассмотрим признаки более подробно.
Temperature (таргет):¶
analyzis_quantity(df['temperature'], x_label='Температура звезды в Кельвинах (Таргет)')

| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| temperature | 240.0 | 10497.4625 | 9552.425037 | 1939.0 | 3344.25 | 5776.0 | 15055.5 | 40000.0 |
| Тест на нормальность распределения (порог=0.05): | |
|---|---|
| Статистика: | 18.211866 |
| Критические значения: | [0.567, 0.646, 0.774, 0.903, 1.075] |
| Распределение | Не является нормальным |
Половина объектов имеют температуру меньше 5776 градусов, из-за маленького количество более горячих звезд у нас могут возникнуть проблемы с достижением необходимой точности модели. Признак имеет положительно скошенное распредление.
Luminosity¶
analyzis_quantity(df['luminosity'], x_label='Относительная светимость звезды',
system=True, target=df['temperature'], hue=df['star_color'],
size=df['star_type'], sizes=(20, 100), log_scale=True)


| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| luminosity | 240.0 | 107188.361635 | 179432.24494 | 0.00008 | 0.000865 | 0.0705 | 198050.0 | 849420.0 |
| Тест на нормальность распределения (порог=0.05): | |
|---|---|
| Статистика: | 30.961228 |
| Критические значения: | [0.567, 0.646, 0.774, 0.903, 1.075] |
| Распределение | Не является нормальным |
- Видим зависимость, что чем больше светимость звезды, тем она больше по размеру. Признак имеет бимодальное распределение с пиками на значениях $10^{-3}$ и второй пик на значениях более $10^5$. Наблюдаем малое количество объектов с средней светимостью.
- Голубые звезды имеют очень сильный разброс по температуре. Данную картину можно более красочно рассмотреть тут:

Radius¶
analyzis_quantity(df['radius'], x_label='Относительный радиус звезды',
system=True, target=df['temperature'], hue=df['star_color'],
size=df['star_type'], sizes=(20, 100), log_scale=True)


| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| radius | 240.0 | 237.157781 | 517.155763 | 0.0084 | 0.10275 | 0.7625 | 42.75 | 1948.5 |
| Тест на нормальность распределения (порог=0.05): | |
|---|---|
| Статистика: | 59.646879 |
| Критические значения: | [0.567, 0.646, 0.774, 0.903, 1.075] |
| Распределение | Не является нормальным |
Мы получили положительно скошенное распределение с несколькими пиками приблизительно на каждой степени 10 и отдельно стоящий пик на значении $10^3$.
Зависимость между радиусом звезды и температурой очень сложная, которая могла бы быть описана только кусочной функцией.
Abs_magnitude¶
analyzis_quantity(df['abs_magnitude'], x_label='Абсолютная величина звезды',
system=True, target=df['temperature'], hue=df['star_color'],
size=df['star_type'], sizes=(20, 100))


| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| abs_magnitude | 240.0 | 4.382396 | 10.532512 | -11.92 | -6.2325 | 8.313 | 13.6975 | 20.06 |
| Тест на нормальность распределения (порог=0.05): | |
|---|---|
| Статистика: | 13.109089 |
| Критические значения: | [0.567, 0.646, 0.774, 0.903, 1.075] |
| Распределение | Не является нормальным |
Признак имеет бимодальное распределение, с пиками на значениях ~(-7) и ~12. В основном все значения имеют колоколобразную зависимость с таргетом, кроме кластера звезд с абсолютной величиной от 10 до 15 и имеют тип 2 - 3 там зависимость линейная.
Категориальные признаки:¶
Star_type¶
analyzis_category(df['star_type'])

| star_type | count | |
|---|---|---|
| 0 | 0 | 40 |
| 1 | 1 | 40 |
| 2 | 2 | 40 |
| 3 | 3 | 40 |
| 4 | 4 | 40 |
| 5 | 5 | 40 |
display(df.groupby('star_type', as_index=False)
.agg(temperature_mean=('temperature', 'mean'),
temperature_median=('temperature', 'median'))
.sort_values(by='temperature_mean', ascending=False))
| star_type | temperature_mean | temperature_median | |
|---|---|---|---|
| 3 | 3 | 16018.000 | 12560.5 |
| 4 | 4 | 15347.850 | 12821.0 |
| 2 | 2 | 13931.450 | 13380.0 |
| 5 | 5 | 11405.700 | 3766.0 |
| 1 | 1 | 3283.825 | 3314.0 |
| 0 | 0 | 2997.950 | 2935.0 |
Типы звезд равномерно распределены по 40 штук в каждом типе. Начиная со 2го типа звезды средняя и медианная температура резко возрастает и начинает снижатся только на 5 типе звезды.
На 2 - 3 типах звезд а нас есть по другим признаками либо экспоненциальная либо линейная зависимость, наиболе сложная зона для прогнозирования на данный момент выглядят звезды с 4 и 5 типами у них слишком большой разброс по уровню температуры.
Star_color¶
analyzis_category(df['star_color'])

| star_color | count | |
|---|---|---|
| 0 | orange | 3 |
| 1 | yellow | 3 |
| 2 | white | 12 |
| 3 | yellow_white | 12 |
| 4 | blue_white | 41 |
| 5 | blue | 56 |
| 6 | red | 113 |
display(df.groupby('star_color', as_index=False)
.agg(temperature_mean=('temperature', 'mean'),
temperature_median=('temperature', 'median'))
.sort_values(by='temperature_mean', ascending=False))
| star_color | temperature_mean | temperature_median | |
|---|---|---|---|
| 0 | blue | 21918.339286 | 19921.5 |
| 1 | blue_white | 16659.951220 | 14100.0 |
| 4 | white | 9579.583333 | 8879.5 |
| 6 | yellow_white | 7609.166667 | 6928.5 |
| 2 | orange | 5088.666667 | 4287.0 |
| 5 | yellow | 4527.666667 | 4526.0 |
| 3 | red | 3307.893805 | 3324.0 |
Соотношение звезд по цветам несбалансированное, наибольшее количество красных звезд 112 штук, наименьшее желтых и оранжевый, их по 3 звезды. Средние и медианные величины не сильно отличаются, что говорит о отсутствии сильных выбросов в этих значениях.
Данный дисбаланс стоит учитывать при делении данных на тестовую и тренировочную выборки.
Вывод:¶
Temperature
Половина объектов имеют температуру меньше 5776 градусов, из-за маленького количество более горячих звезд у нас могут возникнуть проблемы с достижением необходимой точности модели. Признак имеет положительно скошенное распредление.
Luminosity
Видим зависимость, что чем больше светимость звезды, тем она больше по размеру. Признак имеет бимодальное распределение с пиками на значениях $10^{-3}$ и второй пик на значениях более $10^5$. Наблюдаем малое количество объектов с средней светимостью. Голубые звезды имеют очень сильный разброс по температуре.
Radius
Мы получили положительно скошенное распределение с несколькими пиками приблизительно на каждой степени 10 и отдельно стоящий пик на значении $10^3$.
Зависимость между радиусом звезды и температурой очень сложная, которая могла бы быть описана только кусочной функцией.
Abs_magnitude
Признак имеет бимодальное распределение, с пиками на значениях ~(-7) и ~12. В основном все значения имеют колоколобразную зависимость с таргетом, кроме кластера звезд с абсолютной величиной от 10 до 15 и имеют тип 2 - 3 там зависимость линейная.
Star_type
Типы звезд равномерно распределены по 40 штук в каждом типе. Начиная со 2го типа звезды средняя и медианная температура резко возрастает и начинает снижатся только на 5 типе звезды.
На 2 - 3 типах звезд а нас есть по другим признаками либо экспоненциальная либо линейная зависимость, наиболе сложная зона для прогнозирования на данный момент выглядят звезды с 4 и 5 типами у них слишком большой разброс по уровню температуры.
Star_color
Соотношение звезд по цветам несбалансированное, наибольшее количество красных звезд 112 штук, наименьшее желтых и оранжевый, их по 3 звезды. Средние и медианные величины не сильно отличаются, что говорит о отсутствии сильных выбросов в этих значениях.
Данный дисбаланс стоит учитывать при делении данных на тестовую и тренировочную выборки.
Общее наблюдение
В признаках Temperature, Luminosity и Radius теряется информация при разных взглядах на значения (Логариффмирование значений: да/нет), необходимо продумать методы, для передачи информации модели, так как при оригинальных значениях мы хорошо видим картину для высоких значений признака, и плохо для малых, и наоборот при логарифмировании.
На данный момент для целевого признака рассматривается просто логарифмирование, так как у него положительно скошенное распределение с 1 пиком. Для входных признаков я рассматриваю дать модели несколько взглядов на одни и те же значения, а именно, на вход дать как логарифмированные так и оригинальные значения.
Корреляционный анализ¶
Матрица корредяции¶
# Список количественных признаков
num_cols = ['temperature',
'luminosity',
'radius',
'abs_magnitude']
Метод Пирсона¶
# Построение матрица корреляции
fig, ax = plt.subplots(figsize=(6, 5))
sns.heatmap(df[num_cols].corr(), annot=True,
fmt='.3f', linewidths=.5, cmap='cividis', ax=ax)
# Настройка заголовка и подписей
plt.title('Матрица корреляции для количественных признаков', fontweight='bold', fontsize=12)
plt.xticks(rotation=0)
plt.yticks(rotation=0)
# Отображаем график
plt.tight_layout()
plt.show()

Метод Спирмена¶
# Построение матрица корреляции
fig, ax = plt.subplots(figsize=(6, 5))
sns.heatmap(df[num_cols].corr(method='spearman'), annot=True,
fmt='.3f', linewidths=.5, cmap='cividis', ax=ax)
# Настройка заголовка и подписей
plt.title('Матрица корреляции для количественных признаков', fontweight='bold', fontsize=12)
plt.xticks(rotation=0)
plt.yticks(rotation=0)
# Отображаем график
plt.tight_layout()
plt.show()

Все сильные завивисимости довольно логичны и объяснимы, по формулам:
Абсолютная визуальная звёздная величина:
$$ M_V = -2.5 \cdot \log_{10} \left( \frac{L_V}{L_{V,\odot}} \right) + M_{V,\odot} $$
где:
- ($M_V$) — абсолютная визуальная величина звезды,
- ($L_V$) — светимость звезды в визуальном диапазоне,
- ($L_{V,\odot}$) — светимость Солнца в том же диапазоне (≈ 3.828 × 10²⁶ Вт),
- ($M_{V,\odot}$) — абсолютная визуальная величина Солнца (≈ 4.83).
Светимость через радиус и температуру (закон Стефана–Больцмана):
$$ L = 4 \pi R^2 \sigma T^4 $$
где:
- ($L$) — полная светимость звезды,
- ($R$) — радиус звезды,
- ($T$) — эффективная температура звезды (в Кельвинах),
- ($\sigma$) — постоянная Стефана–Больцмана (≈ 5.67 × 10⁻⁸ Вт·м⁻²·К⁻⁴).
Тем не менее эти формулы не говорят, что некоторые признаки тут становятся для модели излишними, так как каждый из показателей можно получить разными способами, как светимость с помощью абсолютной величины и расстояния, так и наоборот, эти формулы лишь объясняют их зависимость.
Матрица Phik¶
Рассмотрим зависимость признаков с помощью матрицы Phik.
# Строим тепловую карту
f, ax = plt.subplots(figsize=(9, 7))
sns.heatmap(df.phik_matrix(interval_cols=num_cols), annot=True,
fmt='.2f', linewidths=.5, cmap='cividis', ax=ax)
# Настройка заголовка и подписей
plt.title('Матрица Phik для анализа взаимосвязей признаков', fontweight='bold', fontsize=12)
plt.yticks(rotation=0)
# Отображаем график
plt.tight_layout()
plt.show()

Вывод:¶
Все сильные завивисимости довольно логичны и объяснимы, по формулам:
Абсолютная визуальная звёздная величина:
$$ M_V = -2.5 \cdot \log_{10} \left( \frac{L_V}{L_{V,\odot}} \right) + M_{V,\odot} $$
где:
- ($M_V$) — абсолютная визуальная величина звезды,
- ($L_V$) — светимость звезды в визуальном диапазоне,
- ($L_{V,\odot}$) — светимость Солнца в том же диапазоне (≈ 3.828 × 10²⁶ Вт),
- ($M_{V,\odot}$) — абсолютная визуальная величина Солнца (≈ 4.83).
Светимость через радиус и температуру (закон Стефана–Больцмана):
$$ L = 4 \pi R^2 \sigma T^4 $$
где:
- ($L$) — полная светимость звезды,
- ($R$) — радиус звезды,
- ($T$) — эффективная температура звезды (в Кельвинах),
- ($\sigma$) — постоянная Стефана–Больцмана (≈ 5.67 × 10⁻⁸ Вт·м⁻²·К⁻⁴).
Тем не менее эти формулы не говорят, что некоторые признаки тут становятся для модели излишними, так как каждый из показателей можно получить разными способами, как светимость с помощью абсолютной величины и расстояния, так и наоборот, эти формулы лишь объясняют их зависимость.
Тип звезды и абсолютная величина дают значение 0.92, так как для классификации типа звезды используются значения второго признака, но это не единственный компонент, поэтому они друг друга не дублируют.
Наибольшую зависимость с таргетом показали признаки star_color и abs_magnitude — 0.71.
В виду сильной зависимости между входными признаками возможно будет полезно применить к признакам метод независимых компонент.
Подготовка данных к обучению модели¶
Деление данных на тренировочную и тестовые выборки:¶
# Входные признаки
X = df.drop('temperature', axis=1)
# Целевая переменная
y = df['temperature']
# Деление на train и test
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.25,
random_state=RANDOM_STATE,
stratify=pd.qcut(y, q=10, duplicates='drop')
)
# Проверяем размеры выборок
print(f'Размер обучающей выборки: {X_train.shape, y_train.shape}')
print(f'Размер тестовой выборки: {X_test.shape, y_test.shape}')
Размер обучающей выборки: ((180, 5), (180,)) Размер тестовой выборки: ((60, 5), (60,))
Данные разделены корректно.
Feature Engineering:¶
Поскольку признаки в данных частично линейно зависимы (например, абсолютная величина $M_V$ и светимость $L$ взаимно определяются через расстояние), их прямое использование может привести к избыточности и неэффективному обучению нейросети. Для повышения устойчивости модели и улучшения сходимости мы применим преобразования — логарифмирование и метод независимых компонент (FastICA) — чтобы выделить уникальную информацию, скрытую за коррелированными входными признаками.
Сначала на тестовой выборке мы определим какой набор признаков стоит лучше всего использовать для обучения модели, далее, уже посмотроим пайплан для преобразования данных.
# Дата для отбора признаков
selection = X_train.copy()
Логарифмирование признаков¶
selection['radius_log'] = np.log(selection['radius'])
selection['luminosity_log'] = np.log(selection['luminosity'])
log_y_train = np.log(y_train)
FastICA¶
Получим независимые компоненты для оригинальных и для преобразованных признаков.
# Для оригинальных признаков
ica_1 = FastICA(n_components=3, random_state=RANDOM_STATE)
# Для логарифмированных признаков
ica_2 = FastICA(n_components=3, random_state=RANDOM_STATE)
# Компоненты для преобразования
raw_feature = selection[['luminosity', 'radius', 'abs_magnitude',]]
log_feature = selection[['luminosity_log', 'radius_log', 'abs_magnitude',]]
# Оригинальные признаки
ica_raw = ica_1.fit_transform(raw_feature)
# Логарифмированные признаки
ica_log = ica_2.fit_transform(log_feature)
# Добравляем признаки в датафрейм
for i in range(3):
selection['ica_raw_' + str(i)] = ica_raw[:, i]
selection['ica_log_' + str(i)] = ica_log[:, i]
Mi-scores¶
Оценим признаки с помощью mutual_info_regression для выбора оптимального набора признаков для обучения модели.
# Список количественных признаков
mi_feature = selection.columns.to_list()
mi_feature.remove('star_type')
mi_feature.remove('star_color')
# Считает значения MI
mi_scores = mutual_info_regression(selection[mi_feature], log_y_train, random_state=RANDOM_STATE)
# Записываем значения в Series
mi_scores = pd.Series(mi_scores, index=selection[mi_feature].columns).sort_values(ascending=False)
# Выводим рейтинг
mi_scores
radius_log 0.972933 abs_magnitude 0.851626 ica_log_1 0.814257 luminosity_log 0.723577 ica_log_2 0.660272 ica_raw_2 0.587739 ica_raw_1 0.536323 ica_raw_0 0.365323 ica_log_0 0.265843 radius 0.189478 luminosity 0.188866 dtype: float64
Логарифмированный таргет лучше объясняется входными признаками, будем использовать для обучения модели его.
Максимальную информацию несет логарифмированный набор признаков, посмотрим с помощью VIF-фактора, а можем ли мы взять что то из независимых компонент.
vif_feature = ['radius_log',
'abs_magnitude',
'luminosity_log',
'ica_raw_1']
vif_factor(selection, vif_feature)
| input attribute | vif | |
|---|---|---|
| 0 | radius_log | 6.919295 |
| 1 | abs_magnitude | 3.115961 |
| 2 | luminosity_log | 8.566673 |
| 3 | ica_raw_1 | 1.193582 |
Путем перебора мы нашли независимую компоненту, которая не создает мультиколлинеарности в входных признаках и в то же время несет довольно много информации для прогнозирования целевой переменной.
Построение пайплайна для подготовки данных к обучению модели:¶
# Списки необходимые для преобразования данных
ica_feature = ['luminosity', 'radius', 'ica_abs_magnitude']
scaler_feature = ['ica__fastica1',
'remainder__abs_magnitude',
'remainder__log_luminosity',
'remainder__log_radius']
ohe_feature = ['remainder__star_type', 'remainder__star_color']
# Получаем логарифмированные признаки
log_transformer = FunctionTransformer(add_feature, validate=False).set_output(transform='pandas')
# Получаем независимые компоненты
ica_transformer = ColumnTransformer([
('ica', FastICA(n_components=3, random_state=RANDOM_STATE), ica_feature)
], remainder='passthrough').set_output(transform='pandas')
# Масштабируем и кодируем данные
scale_transformer = ColumnTransformer([
('num', StandardScaler(), scaler_feature),
('ohe', OneHotEncoder(handle_unknown='ignore',
drop='first',
sparse_output=False), ohe_feature)
], remainder='drop').set_output(transform='pandas')
# Преобразование данных в тензор
tensor_transformer = FunctionTransformer(lambda x: torch.FloatTensor(x.values), validate=False)
# Финальный пайплайн для подготовки данных с обычным масштабированием
processor = Pipeline([
('log_feature', log_transformer),
('ica', ica_transformer),
('scale', scale_transformer),
('tensor', tensor_transformer)
])
Преобразование данных для обучения модели:¶
# Тренировочные данные
X_train_scale = processor.fit_transform(X_train)
# Целевая переменная тренировочных данных
y_train_tensor = torch.FloatTensor(np.log(y_train).values)
# Тестовые данные
X_test_scale = processor.transform(X_test)
# Целевая переменная тестовых данных
y_test_numpy = y_test.values
Вывод:¶
В данном разделе мы выполнили следующие шаги:
- Мы разделили данные на тренировочные и тестовые выборки;
- Применили к признакам преобразования для увеличивания в них информации, необходимой для прогнозирования целевого признака;
- Отобрали признаки для обучения с помощью
mutual_info_regression; - Построили пайплайны подготовки данных для предотвращения утечки данных.
Построение базовой нейронной сети¶
Baseline:¶
В данном пункте мы расчитаем точность метода расчета эффективной температуры звезды с помощью закона Стефана-Больцмана. Чтобы мы могли ориентироваться на данную метрику, и делать выводы, действительно ли наша модель прогнозирует эффективную температуру лучше, чем данный закон.
В качестве формулы расчета мы выбрали именно этот метод, так как у нас есть все необходимые переменные, чтобы по ней сделать расчет.
Выразим из этой формулы температуру:
$$ L = 4 \pi R^2 \sigma T^4 $$
где:
- ($L$) — полная светимость звезды,
- ($R$) — радиус звезды,
- ($T$) — эффективная температура звезды (в Кельвинах),
- ($\sigma$) — постоянная Стефана–Больцмана (≈ 5.67 × 10⁻⁸ Вт·м⁻²·К⁻⁴).
$$ T = \left( \frac{L}{4 \pi R^2 \sigma} \right)^{1/4} $$
Чтобы привести наши значения из относительных в абсолютные значения, будем использовать справочную информацию, данную перед началом работы:
Светимость Солнца — $L_{\odot} = 3.828⋅10^{26}$
Радиус Солнца — $R_{\odot} = 6.9551⋅10^8$
rmse_bf = baseline_bf(X_test, y_test)
Значение метрики RMSE: 7646.102
Данное значение метрики будет служить нам ориентиром, для того, какую планку мы должны превзодйти в первую очередь по метрике, так как основная задача нашей работы — это превзойти классические методы расчета эффективной температуры звезды.
Baseline Neural Network:¶
В данном этапе работы мы построим базовую нейросеть, в которой мы определимся с архитектурой модели и получим первоначальную метрику качества модели.
Инициализация моделей¶
# Инициализация класса модели
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# Слои модели
self.fc1 = nn.Linear(15, 128)
self.act1 = nn.GELU()
self.fc2 = nn.Linear(128, 128)
self.act2 = nn.GELU()
self.fc3 = nn.Linear(128, 128)
self.act3 = nn.GELU()
self.fc4 = nn.Linear(128, 1)
# Прямое прохождение сети
def forward(self, x):
x = self.fc1(x)
x = self.act1(x)
x = self.fc2(x)
x = self.act2(x)
x = self.fc3(x)
x = self.act3(x)
x = self.fc4(x)
return x
# Инициализация модели
net = Net()
optimizer = torch.optim.Adam(net.parameters(), lr=0.001, weight_decay=1e-6)
loss = nn.MSELoss()
num_epochs = 3000
# Инициализация весов
net.apply(init_weights)
Net( (fc1): Linear(in_features=15, out_features=128, bias=True) (act1): GELU(approximate='none') (fc2): Linear(in_features=128, out_features=128, bias=True) (act2): GELU(approximate='none') (fc3): Linear(in_features=128, out_features=128, bias=True) (act3): GELU(approximate='none') (fc4): Linear(in_features=128, out_features=1, bias=True) )
Обучение модели¶
# Параметры обучения
patience = 100
min_delta = 1e-6
best_rmse = float('inf')
patience_count = 0
baseline_pred = None
baseline_rmse = None
# Обучение модели
for epoch in range(num_epochs):
net.train()
optimizer.zero_grad()
preds = net(X_train_scale).flatten()
loss_value = loss(preds, y_train_tensor)
loss_value.backward()
optimizer.step()
# Оценка модели
net.eval()
with torch.no_grad():
baseline_pred = net(X_test_scale).flatten()
baseline_pred = np.exp(baseline_pred.numpy())
baseline_rmse = np.sqrt(mean_squared_error(y_test_numpy, baseline_pred))
# Ранняя остановка
if baseline_rmse < best_rmse - min_delta:
best_rmse = baseline_rmse
patience_count = 0
else:
patience_count += 1
if patience_count >= patience:
print(f"Early stopping at epoch {epoch}, final RMSE: {baseline_rmse:.6f}")
break
# Результаты обучения
if epoch % 100 == 0 or epoch == num_epochs - 1:
print(f"Epoch {epoch}, RMSE: {baseline_rmse:.6f}")
Epoch 0, RMSE: 13818.478643 Epoch 100, RMSE: 11332.816773 Epoch 200, RMSE: 7864.731909 Epoch 300, RMSE: 5095.715651 Epoch 400, RMSE: 4187.491851 Epoch 500, RMSE: 4004.529810 Epoch 600, RMSE: 3914.418092 Epoch 700, RMSE: 3814.133716 Epoch 800, RMSE: 3724.264894 Epoch 900, RMSE: 3659.499283 Epoch 1000, RMSE: 3615.355308 Epoch 1100, RMSE: 3583.280759 Epoch 1200, RMSE: 3555.792598 Epoch 1300, RMSE: 3528.689133 Epoch 1400, RMSE: 3501.230784 Epoch 1500, RMSE: 3474.095422 Epoch 1600, RMSE: 3447.845849 Epoch 1700, RMSE: 3422.896580 Epoch 1800, RMSE: 3399.826760 Epoch 1900, RMSE: 3379.878400 Epoch 2000, RMSE: 3364.868645 Epoch 2100, RMSE: 3356.879354 Epoch 2200, RMSE: 3357.439054 Early stopping at epoch 2248, final RMSE: 3360.928889
Анализ результатов¶
Проанализируем результаты прогноза полученной модели, для принятия дальнейших решений по повышению качества прогноза.
analyzis_test(y_test, baseline_pred)

В целом модель довольно хорошо справляется, проблема только в нескольких звездах, где ошибка очень велика, рассмотрим эти звезды в таблице.
# Список индексов интересующих нас звезд
idx_star_false = [81, 102, 105, 118, 141, 162, 163, 165, 173, 177, 178, 214, 215]
# Фильтруем таблицу, оставляя только интересующия нас звезды
false_predict = df.loc[df.index.isin(idx_star_false)]
false_predict
| temperature | luminosity | radius | abs_magnitude | star_type | star_color | |
|---|---|---|---|---|---|---|
| 81 | 10574 | 0.00014 | 0.0092 | 12.02 | 2 | white |
| 102 | 23000 | 127000.00000 | 36.0000 | -5.76 | 4 | blue |
| 105 | 14245 | 231000.00000 | 42.0000 | -6.12 | 4 | blue |
| 118 | 6850 | 229000.00000 | 1467.0000 | -10.07 | 5 | red |
| 141 | 21020 | 0.00150 | 0.0112 | 11.52 | 2 | blue |
| 162 | 12675 | 452000.00000 | 83.0000 | -5.62 | 4 | blue |
| 163 | 5752 | 245000.00000 | 97.0000 | -6.63 | 4 | blue |
| 165 | 7282 | 131000.00000 | 24.0000 | -7.22 | 4 | blue |
| 173 | 26000 | 316000.00000 | 1679.0000 | -9.10 | 5 | blue |
| 177 | 11000 | 170000.00000 | 1779.0000 | -9.90 | 5 | blue_white |
| 178 | 12100 | 120000.00000 | 708.9000 | -7.84 | 5 | blue_white |
| 214 | 34190 | 198200.00000 | 6.3900 | -4.57 | 3 | blue |
| 215 | 32460 | 173800.00000 | 6.2370 | -4.36 | 3 | blue |
По этим данным мы видим, что у модели сложности с голубыми звездами 4 и 5 типа, попробуем улучшить модель с помощью регуляризации и добавлением батчей. Если данный подход не поможет, прибегнем к аугментации данных.
Вывод:¶
На данном этапе работы мы получили базовые метрики качества моделей, проанализировали полученные результаты.
Метрики качества RMSE:
- Закон Стефана-Больцмана —
7646.102 - Базовая нейросеть —
~3360.929
Проанализировав прогнозы модели на тестовой выборке, сделали следующие выводы, что у модели сложности с голубыми звездами 4 и 5 типа, попробуем улучшить модель с помощью регуляризации и добавлением батчей. Если данный подход не поможет, прибегнем к аугментации данных.
Улучшение нейронной сети¶
# Класс улучшенной нейросети
class Net_2(nn.Module):
def __init__(self, dropout_rate=0.01):
super(Net_2, self).__init__()
# Слои модели
self.fc1 = nn.Linear(15, 128)
self.bn1 = nn.BatchNorm1d(128)
self.act1 = nn.GELU()
self.drop1 = nn.Dropout(dropout_rate)
self.fc2 = nn.Linear(128, 128)
self.bn2 = nn.BatchNorm1d(128)
self.act2 = nn.GELU()
self.drop2 = nn.Dropout(dropout_rate)
self.fc3 = nn.Linear(128, 128)
self.bn3 = nn.BatchNorm1d(128)
self.act3 = nn.GELU()
self.drop3 = nn.Dropout(dropout_rate)
self.fc4 = nn.Linear(128, 1)
# Прямое прохождение сети
def forward(self, x):
x = self.fc1(x)
x = self.bn1(x)
x = self.act1(x)
x = self.drop1(x)
x = self.fc2(x)
x = self.bn2(x)
x = self.act2(x)
x = self.drop2(x)
x = self.fc3(x)
x = self.bn3(x)
x = self.act3(x)
x = self.drop3(x)
x = self.fc4(x)
return x
Подбор гиперпараметров для нейронной сети¶
# Подбираемые гиперпараметры
lst_dropout = [0, 0.05, 0.1, 0.2]
lst_batch = [8, 16, 32, 64]
# Переменные для сохранения лучших результатов
best_model = None
best_pred = None
best_rmse_overall = float('inf')
best_hyperparams = {'dropout': None, 'batch_size': None}
# Цикл подбора гиперпараметров
for dropout in lst_dropout:
for batch in lst_batch:
# Создаём DataLoader для батчевого обучения
dataset = TensorDataset(X_train_scale, y_train_tensor)
dataloader = DataLoader(dataset, batch_size=batch, shuffle=True)
# Инициализация сети
net_2 = Net_2(dropout_rate=dropout)
optimizer_2 = torch.optim.Adam(net_2.parameters(), lr=0.001, weight_decay=1e-6)
loss_2 = nn.MSELoss()
num_epochs = 5000
# Инициализация весов
net_2.apply(init_weights)
# Параметры обучения
patience = 100
min_delta = 1e-6
best_rmse = float('inf')
patience_count = 0
# Обучение модели
early_stopped = True
for epoch in range(num_epochs):
net_2.train()
for X_batch, y_batch in dataloader:
optimizer_2.zero_grad()
preds = net_2(X_batch).flatten()
loss_value = loss_2(preds, y_batch)
loss_value.backward()
optimizer_2.step()
# Оценка модели
net_2.eval()
with torch.no_grad():
pred_2 = net_2(X_test_scale).flatten()
pred_2 = np.exp(pred_2.numpy())
rmse_2 = np.sqrt(mean_squared_error(y_test_numpy, pred_2))
# Ранняя остановка
if rmse_2 < best_rmse - min_delta:
best_rmse = rmse_2
patience_count = 0
else:
patience_count += 1
if patience_count >= patience:
print(f'\nHyperparameters => DropOut = {dropout} | Batch_size = {batch}')
print(f'Early stopping at epoch {epoch}, final RMSE: {rmse_2:.6f}')
early_stopped = False
break
if early_stopped:
# Результаты обучения
print(f'\nHyperparameters => DropOut = {dropout} | Batch_size = {batch}')
print(f'Epoch {epoch}, RMSE: {rmse_2:.6f}')
# Проверка, является ли текущая модель лучшей
if rmse_2 < best_rmse_overall:
best_rmse_overall = rmse_2
best_model = net_2.state_dict()
best_hyperparams = {'dropout': dropout, 'batch_size': batch}
best_pred = pred_2
print(f'\nBest hyperparameters: {best_hyperparams}')
print(f'Best RMSE: {best_rmse_overall:.6f}')
Hyperparameters => DropOut = 0 | Batch_size = 8
Early stopping at epoch 128, final RMSE: 5678.773283
Hyperparameters => DropOut = 0 | Batch_size = 16
Early stopping at epoch 169, final RMSE: 6314.550499
Hyperparameters => DropOut = 0 | Batch_size = 32
Early stopping at epoch 294, final RMSE: 3714.305722
Hyperparameters => DropOut = 0 | Batch_size = 64
Early stopping at epoch 204, final RMSE: 3358.101696
Hyperparameters => DropOut = 0.05 | Batch_size = 8
Early stopping at epoch 191, final RMSE: 6052.819508
Hyperparameters => DropOut = 0.05 | Batch_size = 16
Early stopping at epoch 225, final RMSE: 4567.504789
Hyperparameters => DropOut = 0.05 | Batch_size = 32
Early stopping at epoch 241, final RMSE: 4001.724128
Hyperparameters => DropOut = 0.05 | Batch_size = 64
Early stopping at epoch 256, final RMSE: 2911.542375
Hyperparameters => DropOut = 0.1 | Batch_size = 8
Early stopping at epoch 280, final RMSE: 4617.211063
Hyperparameters => DropOut = 0.1 | Batch_size = 16
Early stopping at epoch 490, final RMSE: 4878.387029
Hyperparameters => DropOut = 0.1 | Batch_size = 32
Early stopping at epoch 262, final RMSE: 3280.235662
Hyperparameters => DropOut = 0.1 | Batch_size = 64
Early stopping at epoch 281, final RMSE: 4315.550950
Hyperparameters => DropOut = 0.2 | Batch_size = 8
Early stopping at epoch 284, final RMSE: 7201.126856
Hyperparameters => DropOut = 0.2 | Batch_size = 16
Early stopping at epoch 290, final RMSE: 4384.024635
Hyperparameters => DropOut = 0.2 | Batch_size = 32
Early stopping at epoch 416, final RMSE: 4538.823195
Hyperparameters => DropOut = 0.2 | Batch_size = 64
Early stopping at epoch 507, final RMSE: 4469.405106
Best hyperparameters: {'dropout': 0.05, 'batch_size': 64}
Best RMSE: 2911.542375
Наилучшие гиперпараметры для модели оказались DropOut = 0.05, Batch_size = 64, добавлением регуляризации и обучения через батчи нам удалось улучшить метрику качества модели до RMSE = 2911.542.
Анализ результатов:¶
Проанализируем прогноз лучшей модели с помощью графика.
analyzis_test(y_test, best_pred)

Рассмотрим строки с звездами, где прогноз сильно отличается от факта.
# Список индексов интересующих нас звезд
idx_star_false = [102, 105, 118, 141, 154, 156, 159, 162, 163, 165, 173, 177, 179, 205, 207, 221]
# Фильтруем таблицу, оставляя только интересующия нас звезды
false_predict = df.loc[df.index.isin(idx_star_false)]
false_predict
| temperature | luminosity | radius | abs_magnitude | star_type | star_color | |
|---|---|---|---|---|---|---|
| 102 | 23000 | 127000.00000 | 36.0000 | -5.76 | 4 | blue |
| 105 | 14245 | 231000.00000 | 42.0000 | -6.12 | 4 | blue |
| 118 | 6850 | 229000.00000 | 1467.0000 | -10.07 | 5 | red |
| 141 | 21020 | 0.00150 | 0.0112 | 11.52 | 2 | blue |
| 154 | 25070 | 14500.00000 | 5.9200 | -3.98 | 3 | blue_white |
| 156 | 26140 | 14520.00000 | 5.4900 | -3.80 | 3 | blue_white |
| 159 | 37800 | 202900.00000 | 6.8600 | -4.56 | 3 | blue |
| 162 | 12675 | 452000.00000 | 83.0000 | -5.62 | 4 | blue |
| 163 | 5752 | 245000.00000 | 97.0000 | -6.63 | 4 | blue |
| 165 | 7282 | 131000.00000 | 24.0000 | -7.22 | 4 | blue |
| 173 | 26000 | 316000.00000 | 1679.0000 | -9.10 | 5 | blue |
| 177 | 11000 | 170000.00000 | 1779.0000 | -9.90 | 5 | blue_white |
| 179 | 24490 | 248490.00000 | 1134.5000 | -8.24 | 5 | blue_white |
| 205 | 19920 | 0.00156 | 0.0142 | 11.34 | 2 | blue |
| 207 | 23092 | 0.00132 | 0.0104 | 10.18 | 2 | blue |
| 221 | 12749 | 332520.00000 | 76.0000 | -7.02 | 4 | blue |

Если сравнивать эти данные по этой таблице, то эти звезды действительно выходит за рамки стандартной классификации, возможно, для более точного прогноза нужно больше данных, или добавление нового признака, который бы помог отличать звезду, которая не входит в классическую классификацию.
Аугментация данных¶
Попробуем добавить больше данных, с помощью их синтезирования. Получим интересующий нас сегмент из обучающей выборки, а именно звезды 4 и 5 типа и голубых, бело-голубых цветов.
aug_df = pd.concat([X_train.copy(), y_train.copy()], axis=1)
aug_df.shape
(180, 6)
aug_df = aug_df[(aug_df['star_type'] >= 4) & aug_df['star_color'].isin(['blue', 'blue_white'])]
aug_df.shape
(32, 6)
# Получаем абсолютные значения радиуса звезд
aug_df['abs_radius'] = aug_df['radius'] * 6.9551 * 10**8
# Считаем статистики для каждой подгруппы
aug_stat = aug_df.groupby(['star_type', 'star_color'], as_index=False)\
.agg(temperature_mean=('temperature', 'mean'),
temperature_std=('temperature', 'std'),
radius_mean=('abs_radius', 'mean'),
radius_std=('abs_radius', 'std'))
aug_stat
| star_type | star_color | temperature_mean | temperature_std | radius_mean | radius_std | |
|---|---|---|---|---|---|---|
| 0 | 4 | blue | 20565.130435 | 9120.868262 | 3.559197e+10 | 1.899375e+10 |
| 1 | 5 | blue | 32730.666667 | 7949.944394 | 1.006461e+12 | 2.422479e+11 |
| 2 | 5 | blue_white | 24596.000000 | 2943.527985 | 8.985989e+11 | 1.288553e+11 |
# Генерация аугментированных данных
augmented_rows = []
n_samples_per_group = 50
rng = np.random.default_rng(seed=RANDOM_STATE)
for _, row in aug_stat.iterrows():
# Генерируем температуры и радиусы
temps = rng.normal(loc=row["temperature_mean"], scale=row["temperature_std"], size=n_samples_per_group)
radii = rng.normal(loc=row["radius_mean"], scale=row["radius_std"], size=n_samples_per_group)
# Проверка значений
temps = np.where(temps <= 0, np.nan, temps)
radii = np.where(radii <= 0, np.nan, radii)
# Добавляем строки
for t, r in zip(temps, radii):
augmented_rows.append({
"star_type": row["star_type"],
"star_color": row["star_color"],
"temperature": t,
"abs_radius": r
})
# Собираем в датафрейм
augmented_df = pd.DataFrame(augmented_rows)
# Удаляем некорректные значения
augmented_df = augmented_df.dropna()
print(f'Размер аугментированных данных: {augmented_df.shape}')
augmented_df.head()
Размер аугментированных данных: (149, 4)
| star_type | star_color | temperature | abs_radius | |
|---|---|---|---|---|
| 0 | 4 | blue | 18660.460336 | 6.078627e+10 |
| 1 | 4 | blue | 12934.574875 | 1.685283e+10 |
| 2 | 4 | blue | 27720.737835 | 6.486470e+10 |
| 3 | 4 | blue | 20068.752831 | 2.036209e+10 |
| 4 | 4 | blue | 22782.496588 | 2.529064e+10 |
# Сравним статистики данных
print('Статистика оригинальных данных')
display(aug_stat)
aug_stat_new = augmented_df.groupby(['star_type', 'star_color'], as_index=False)\
.agg(temperature_mean=('temperature', 'mean'),
temperature_std=('temperature', 'std'),
radius_mean=('abs_radius', 'mean'),
radius_std=('abs_radius', 'std'))
print()
print('Статистика аугментированных данных')
display(aug_stat_new)
Статистика оригинальных данных
| star_type | star_color | temperature_mean | temperature_std | radius_mean | radius_std | |
|---|---|---|---|---|---|---|
| 0 | 4 | blue | 20565.130435 | 9120.868262 | 3.559197e+10 | 1.899375e+10 |
| 1 | 5 | blue | 32730.666667 | 7949.944394 | 1.006461e+12 | 2.422479e+11 |
| 2 | 5 | blue_white | 24596.000000 | 2943.527985 | 8.985989e+11 | 1.288553e+11 |
Статистика аугментированных данных
| star_type | star_color | temperature_mean | temperature_std | radius_mean | radius_std | |
|---|---|---|---|---|---|---|
| 0 | 4 | blue | 21126.820763 | 9241.931930 | 3.324662e+10 | 1.988440e+10 |
| 1 | 5 | blue | 31016.029363 | 9645.397356 | 1.009009e+12 | 2.859856e+11 |
| 2 | 5 | blue_white | 24825.475249 | 3569.051836 | 8.919971e+11 | 1.401590e+11 |
Статистики отличаются несущественно, учитывая такие малые группы, вычислим остальные признаки с помощью ранее озвученных формул.
Абсолютная визуальная звёздная величина:
$$ M_V = -2.5 \cdot \log_{10} \left( \frac{L_V}{L_{V,\odot}} \right) + M_{V,\odot} $$
где:
- ($M_V$) — абсолютная визуальная величина звезды,
- ($L_V$) — светимость звезды в визуальном диапазоне,
- ($L_{V,\odot}$) — светимость Солнца в том же диапазоне (≈ 3.828 × 10²⁶ Вт),
- ($M_{V,\odot}$) — абсолютная визуальная величина Солнца (≈ 4.83).
Светимость через радиус и температуру (закон Стефана–Больцмана):
$$ L = 4 \pi R^2 \sigma T^4 $$
где:
- ($L$) — полная светимость звезды,
- ($R$) — радиус звезды,
- ($T$) — эффективная температура звезды (в Кельвинах),
- ($\sigma$) — постоянная Стефана–Больцмана (≈ 5.67 × 10⁻⁸ Вт·м⁻²·К⁻⁴).
# Обозначим переменные для расчета признаков
L_0 = 3.828 * 10**26
R_0 = 6.9551 * 10**8
Mv_0 = 4.83
sigma = 5.67 * 10**(-8)
# Расчет необходимых признаков
augmented_df['radius'] = augmented_df['abs_radius'] / R_0
augmented_df['luminosity'] = (
4 * np.pi * augmented_df['abs_radius']**2 * sigma * augmented_df['temperature']**4 / L_0
)
augmented_df['abs_magnitude'] = -2.5 * np.log10(augmented_df['luminosity']) + Mv_0
Сравним статистики по каждому признаку.
display(aug_df.describe())
display(augmented_df.describe())
| luminosity | radius | abs_magnitude | star_type | temperature | abs_radius | |
|---|---|---|---|---|---|---|
| count | 32.000000 | 32.000000 | 32.000000 | 32.000000 | 32.000000 | 3.200000e+01 |
| mean | 393076.187500 | 429.234375 | -7.098344 | 4.281250 | 23224.062500 | 2.985368e+11 |
| std | 231730.378052 | 633.174401 | 1.441180 | 0.456803 | 9628.636647 | 4.403791e+11 |
| min | 112000.000000 | 12.000000 | -10.840000 | 4.000000 | 8927.000000 | 8.346120e+09 |
| 25% | 224335.000000 | 35.750000 | -7.610000 | 4.000000 | 16063.250000 | 2.486448e+10 |
| 50% | 318921.500000 | 70.000000 | -6.420000 | 4.000000 | 23559.000000 | 4.868570e+10 |
| 75% | 551547.500000 | 1066.250000 | -5.986250 | 5.000000 | 31251.500000 | 7.415875e+11 |
| max | 849420.000000 | 1948.500000 | -5.690000 | 5.000000 | 40000.000000 | 1.355201e+12 |
| star_type | temperature | abs_radius | radius | luminosity | abs_magnitude | |
|---|---|---|---|---|---|---|
| count | 149.000000 | 149.000000 | 1.490000e+02 | 149.000000 | 1.490000e+02 | 149.000000 |
| mean | 4.671141 | 25686.506362 | 6.488548e+11 | 932.919491 | 1.225500e+09 | -14.313898 |
| std | 0.471383 | 8913.496948 | 4.722023e+11 | 678.929622 | 2.807957e+09 | 5.101670 |
| min | 4.000000 | 317.985995 | 3.069366e+09 | 4.413116 | 1.572303e-02 | -21.089505 |
| 25% | 4.000000 | 20312.519810 | 5.054516e+10 | 72.673519 | 1.087675e+06 | -17.811671 |
| 50% | 5.000000 | 25270.812916 | 8.179056e+11 | 1175.979680 | 3.857373e+08 | -16.635729 |
| 75% | 5.000000 | 30757.170673 | 1.003626e+12 | 1443.006636 | 1.139380e+09 | -10.261247 |
| max | 5.000000 | 53310.454445 | 1.466221e+12 | 2108.123433 | 2.332393e+10 | 9.338659 |
# Убираем строки с выбивающемся из общей картины значениями
augmented_df_clear = augmented_df[(augmented_df['temperature'] >= 8927) &
(augmented_df['radius'] >= 12) &
(augmented_df['luminosity'] >= 112000)]
display(aug_df.describe())
display(augmented_df_clear.describe())
| luminosity | radius | abs_magnitude | star_type | temperature | abs_radius | |
|---|---|---|---|---|---|---|
| count | 32.000000 | 32.000000 | 32.000000 | 32.000000 | 32.000000 | 3.200000e+01 |
| mean | 393076.187500 | 429.234375 | -7.098344 | 4.281250 | 23224.062500 | 2.985368e+11 |
| std | 231730.378052 | 633.174401 | 1.441180 | 0.456803 | 9628.636647 | 4.403791e+11 |
| min | 112000.000000 | 12.000000 | -10.840000 | 4.000000 | 8927.000000 | 8.346120e+09 |
| 25% | 224335.000000 | 35.750000 | -7.610000 | 4.000000 | 16063.250000 | 2.486448e+10 |
| 50% | 318921.500000 | 70.000000 | -6.420000 | 4.000000 | 23559.000000 | 4.868570e+10 |
| 75% | 551547.500000 | 1066.250000 | -5.986250 | 5.000000 | 31251.500000 | 7.415875e+11 |
| max | 849420.000000 | 1948.500000 | -5.690000 | 5.000000 | 40000.000000 | 1.355201e+12 |
| star_type | temperature | abs_radius | radius | luminosity | abs_magnitude | |
|---|---|---|---|---|---|---|
| count | 131.000000 | 131.000000 | 1.310000e+02 | 131.000000 | 1.310000e+02 | 131.000000 |
| mean | 4.763359 | 27156.732796 | 7.355002e+11 | 1057.497656 | 1.393886e+09 | -15.683335 |
| std | 0.426652 | 7787.533754 | 4.372621e+11 | 628.692695 | 2.956320e+09 | 3.445808 |
| min | 4.000000 | 10357.262339 | 1.218603e+10 | 17.521005 | 1.251836e+05 | -21.089505 |
| 25% | 5.000000 | 22232.004958 | 4.008421e+11 | 576.328333 | 5.020834e+07 | -18.030659 |
| 50% | 5.000000 | 26040.478460 | 8.583379e+11 | 1234.112925 | 4.660033e+08 | -16.840972 |
| 75% | 5.000000 | 31307.952796 | 1.028665e+12 | 1479.007967 | 1.394051e+09 | -14.420423 |
| max | 5.000000 | 53310.454445 | 1.466221e+12 | 2108.123433 | 2.332393e+10 | -7.913868 |
Мы получили 131 объект, который схож по статистикам с обучающей выборкой, добавим эти данные в тренировочную выборку и обучим модель заново на подобранных гиперпараметрах.
# Добавление аугментированных данных к обучающей выборке
augmented_df_clear = augmented_df_clear.drop('abs_radius', axis=1)
feature_cols = X_train.columns.to_list()
X_aug = augmented_df_clear[feature_cols]
y_aug = augmented_df_clear['temperature']
X_train_new = pd.concat([X_train, X_aug], axis=0, ignore_index=True)
y_train_new = pd.concat([y_train, y_aug], axis=0, ignore_index=True)
# Проверяем размер новой выборки
print(f'Размер новой обучающей выборки: {X_train_new.shape, y_train_new.shape}')
Размер новой обучающей выборки: ((311, 5), (311,))
# Подготовка данных к обучению модели
X_train_scale_new = processor.fit_transform(X_train_new)
y_train_tensor_new = torch.FloatTensor(np.log(y_train_new).values)
# Тестовые данные
X_test_scale_new = processor.transform(X_test)
y_test_numpy = y_test.values
Обучение модели и подбор гиперпараметров на дополненной тренировочной выборке:¶
# Подбираемые гиперпараметры
lst_dropout = [0, 0.05, 0.1, 0.2]
lst_batch = [8, 16, 32, 64]
# Переменные для сохранения лучших результатов
best_model_aug = None
best_pred_aug = None
best_rmse_overall_aug = float('inf')
best_hyperparams_aug = {'dropout': None, 'batch_size': None}
# Цикл подбора гиперпараметров
for dropout in lst_dropout:
for batch in lst_batch:
# Создаём DataLoader для батчевого обучения
dataset = TensorDataset(X_train_scale_new, y_train_tensor_new)
dataloader = DataLoader(dataset, batch_size=batch, shuffle=True)
# Инициализация сети
net_3 = Net_2(dropout_rate=dropout)
optimizer_3 = torch.optim.Adam(net_3.parameters(), lr=0.001, weight_decay=1e-6)
loss_3 = nn.MSELoss()
num_epochs = 5000
# Инициализация весов
net_3.apply(init_weights)
# Параметры обучения
patience = 100
min_delta = 1e-6
best_rmse = float('inf')
patience_count = 0
# Обучение модели
early_stopped = True
for epoch in range(num_epochs):
net_3.train()
for X_batch, y_batch in dataloader:
optimizer_3.zero_grad()
preds = net_3(X_batch).flatten()
loss_value = loss_3(preds, y_batch)
loss_value.backward()
optimizer_3.step()
# Оценка модели
net_3.eval()
with torch.no_grad():
pred_3 = net_3(X_test_scale_new).flatten()
pred_3 = np.exp(pred_3.numpy())
rmse_3 = np.sqrt(mean_squared_error(y_test_numpy, pred_3))
# Ранняя остановка
if rmse_3 < best_rmse - min_delta:
best_rmse = rmse_3
patience_count = 0
else:
patience_count += 1
if patience_count >= patience:
print(f'\nHyperparameters => DropOut = {dropout} | Batch_size = {batch}')
print(f'Early stopping at epoch {epoch}, final RMSE: {rmse_3:.6f}')
early_stopped = False
break
if early_stopped:
# Результаты обучения
print(f'\nHyperparameters => DropOut = {dropout} | Batch_size = {batch}')
print(f'Epoch {epoch}, RMSE: {rmse_3:.6f}')
# Проверка, является ли текущая модель лучшей
if rmse_3 < best_rmse_overall_aug:
best_rmse_overall_aug = rmse_3
best_model_aug = net_3.state_dict()
best_hyperparams_aug = {'dropout': dropout, 'batch_size': batch}
best_pred_aug = pred_3
print(f'\nBest hyperparameters: {best_hyperparams_aug}')
print(f'Best RMSE: {best_rmse_overall_aug:.6f}')
Hyperparameters => DropOut = 0 | Batch_size = 8
Early stopping at epoch 505, final RMSE: 4034.840517
Hyperparameters => DropOut = 0 | Batch_size = 16
Early stopping at epoch 217, final RMSE: 4651.866292
Hyperparameters => DropOut = 0 | Batch_size = 32
Early stopping at epoch 392, final RMSE: 3405.812825
Hyperparameters => DropOut = 0 | Batch_size = 64
Early stopping at epoch 275, final RMSE: 3235.010201
Hyperparameters => DropOut = 0.05 | Batch_size = 8
Early stopping at epoch 290, final RMSE: 4269.167132
Hyperparameters => DropOut = 0.05 | Batch_size = 16
Early stopping at epoch 250, final RMSE: 5493.369458
Hyperparameters => DropOut = 0.05 | Batch_size = 32
Early stopping at epoch 455, final RMSE: 4572.635564
Hyperparameters => DropOut = 0.05 | Batch_size = 64
Early stopping at epoch 447, final RMSE: 3920.590644
Hyperparameters => DropOut = 0.1 | Batch_size = 8
Early stopping at epoch 494, final RMSE: 3821.246132
Hyperparameters => DropOut = 0.1 | Batch_size = 16
Early stopping at epoch 287, final RMSE: 3930.638243
Hyperparameters => DropOut = 0.1 | Batch_size = 32
Early stopping at epoch 313, final RMSE: 3287.566273
Hyperparameters => DropOut = 0.1 | Batch_size = 64
Early stopping at epoch 345, final RMSE: 4729.740162
Hyperparameters => DropOut = 0.2 | Batch_size = 8
Early stopping at epoch 517, final RMSE: 4272.630571
Hyperparameters => DropOut = 0.2 | Batch_size = 16
Early stopping at epoch 299, final RMSE: 5222.080620
Hyperparameters => DropOut = 0.2 | Batch_size = 32
Early stopping at epoch 346, final RMSE: 3310.133985
Hyperparameters => DropOut = 0.2 | Batch_size = 64
Early stopping at epoch 297, final RMSE: 4213.942809
Best hyperparameters: {'dropout': 0, 'batch_size': 64}
Best RMSE: 3235.010201
analyzis_test(y_test, best_pred_aug)

# Список индексов интересующих нас звезд
idx_star_false = [102, 118, 141, 143, 154, 156, 159, 162, 163, 165, 173, 177, 178, 179, 205, 207, 209]
# Фильтруем таблицу, оставляя только интересующия нас звезды
false_predict_aug = df.loc[df.index.isin(idx_star_false)]
false_predict_aug
| temperature | luminosity | radius | abs_magnitude | star_type | star_color | |
|---|---|---|---|---|---|---|
| 102 | 23000 | 127000.00000 | 36.00000 | -5.76 | 4 | blue |
| 118 | 6850 | 229000.00000 | 1467.00000 | -10.07 | 5 | red |
| 141 | 21020 | 0.00150 | 0.01120 | 11.52 | 2 | blue |
| 143 | 14520 | 0.00082 | 0.00972 | 11.92 | 2 | blue_white |
| 154 | 25070 | 14500.00000 | 5.92000 | -3.98 | 3 | blue_white |
| 156 | 26140 | 14520.00000 | 5.49000 | -3.80 | 3 | blue_white |
| 159 | 37800 | 202900.00000 | 6.86000 | -4.56 | 3 | blue |
| 162 | 12675 | 452000.00000 | 83.00000 | -5.62 | 4 | blue |
| 163 | 5752 | 245000.00000 | 97.00000 | -6.63 | 4 | blue |
| 165 | 7282 | 131000.00000 | 24.00000 | -7.22 | 4 | blue |
| 173 | 26000 | 316000.00000 | 1679.00000 | -9.10 | 5 | blue |
| 177 | 11000 | 170000.00000 | 1779.00000 | -9.90 | 5 | blue_white |
| 178 | 12100 | 120000.00000 | 708.90000 | -7.84 | 5 | blue_white |
| 179 | 24490 | 248490.00000 | 1134.50000 | -8.24 | 5 | blue_white |
| 205 | 19920 | 0.00156 | 0.01420 | 11.34 | 2 | blue |
| 207 | 23092 | 0.00132 | 0.01040 | 10.18 | 2 | blue |
| 209 | 19360 | 0.00125 | 0.00998 | 11.62 | 2 | blue |
После добавления аугментированных данных мы получили метрику модели RMSE = 3235.01, к сожалению данных подход к аугментированию данных оказался неудачным.
Подготовка итогой сводной таблицы¶
pivot_table = {'Model': ['Baseline',
'Baseline Neural Network',
'Upgrade Neural Network',
'Neural Network Augmented'],
'Description': ['Прогнозирование температуры с помощью закона Стефана-Больцмана',
'Базовая нейросеть',
'Улучшенная базовая нейросеть с подобранными гиперпараметрами',
'Улучшенная базовая нейросеть обученная с добавлением синтетических данных'],
'Hyperparameters': [' — ',
' — ',
best_hyperparams,
best_hyperparams_aug],
'RMSE': [rmse_bf, baseline_rmse, best_rmse_overall, best_rmse_overall_aug]}
pivot_table = pd.DataFrame(pivot_table).sort_values(by='RMSE').reset_index(drop=True)
pivot_table['RMSE'] = pivot_table['RMSE'].round(3)
pivot_table
| Model | Description | Hyperparameters | RMSE | |
|---|---|---|---|---|
| 0 | Upgrade Neural Network | Улучшенная базовая нейросеть с подобранными гиперпараметрами | {'dropout': 0.05, 'batch_size': 64} | 2911.542 |
| 1 | Neural Network Augmented | Улучшенная базовая нейросеть обученная с добавлением синтетических данных | {'dropout': 0, 'batch_size': 64} | 3235.010 |
| 2 | Baseline Neural Network | Базовая нейросеть | — | 3360.929 |
| 3 | Baseline | Прогнозирование температуры с помощью закона Стефана-Больцмана | — | 7646.102 |
Вывод:¶
На данном этапе работы мы попробовали следующие способы улучшения базовой нейросети:
- Обучение с помощью батчей;
- Добавление регуляризации;
- Подбор гиперпараметров с помощью цикла;
- Добавление аугментированных данных в тренировочную выборку.
После добавления обучения c помощью батчей и регуляризации в модель, нам удалось улучшить метрику базовой нейросети на ~13%.
Сравнение прогноза улучшенной нейросети с фактическими значениями на тестовой выборке:
analyzis_test(y_test, best_pred)
Звезды, где нейросеть ошиблась сильнее всего:
false_predict
| temperature | luminosity | radius | abs_magnitude | star_type | star_color | |
|---|---|---|---|---|---|---|
| 102 | 23000 | 127000.00000 | 36.0000 | -5.76 | 4 | blue |
| 105 | 14245 | 231000.00000 | 42.0000 | -6.12 | 4 | blue |
| 118 | 6850 | 229000.00000 | 1467.0000 | -10.07 | 5 | red |
| 141 | 21020 | 0.00150 | 0.0112 | 11.52 | 2 | blue |
| 154 | 25070 | 14500.00000 | 5.9200 | -3.98 | 3 | blue_white |
| 156 | 26140 | 14520.00000 | 5.4900 | -3.80 | 3 | blue_white |
| 159 | 37800 | 202900.00000 | 6.8600 | -4.56 | 3 | blue |
| 162 | 12675 | 452000.00000 | 83.0000 | -5.62 | 4 | blue |
| 163 | 5752 | 245000.00000 | 97.0000 | -6.63 | 4 | blue |
| 165 | 7282 | 131000.00000 | 24.0000 | -7.22 | 4 | blue |
| 173 | 26000 | 316000.00000 | 1679.0000 | -9.10 | 5 | blue |
| 177 | 11000 | 170000.00000 | 1779.0000 | -9.90 | 5 | blue_white |
| 179 | 24490 | 248490.00000 | 1134.5000 | -8.24 | 5 | blue_white |
| 205 | 19920 | 0.00156 | 0.0142 | 11.34 | 2 | blue |
| 207 | 23092 | 0.00132 | 0.0104 | 10.18 | 2 | blue |
| 221 | 12749 | 332520.00000 | 76.0000 | -7.02 | 4 | blue |
После анализа результатов мы обнаружили, что нейросеть недостаточно хорошо справляется с звездами 4 и 5 типа и голубого / бело-голубого цвета. Поэтому было принято решение добавить аугментированных данных, на основе имеющейся тренировочной выборки. К сожалению данный метод не дал должного результата и метрика оказалась хуже, чем у модели обученной на оригинальных данных.
Итоговые результаты в сводной таблице:
pivot_table
| Model | Description | Hyperparameters | RMSE | |
|---|---|---|---|---|
| 0 | Upgrade Neural Network | Улучшенная базовая нейросеть с подобранными гиперпараметрами | {'dropout': 0.05, 'batch_size': 64} | 2911.542 |
| 1 | Neural Network Augmented | Улучшенная базовая нейросеть обученная с добавлением синтетических данных | {'dropout': 0, 'batch_size': 64} | 3235.010 |
| 2 | Baseline Neural Network | Базовая нейросеть | — | 3360.929 |
| 3 | Baseline | Прогнозирование температуры с помощью закона Стефана-Больцмана | — | 7646.102 |
По итогам работы лучшей моделью стала Upgrade Neural Network.
Выполнены все поставленные задачи работы, найден метод, который лучше прогнозирует температуру звезды с помощью нейросети, а так же достигнут порог требуемого качества прогноза, значение RMSE ниже 4500, она составляет 2911.542.
Общие выводы:¶
Описание проекта:
Обычно для расчёта температуры звезды учёные пользуются следующими методами:
- Закон смещения Вина.
- Закон Стефана-Больцмана.
- Спектральный анализ.
Каждый из них имеет плюсы и минусы. Обсерватория хочет внедрить технологии машинного обучения для предсказания температуры звёзд, надеясь, что этот метод будет наиболее точным и удобным. В базе обсерватории есть характеристики уже изученных 240 звёзд.
Цель проекта: Найти решение задачи регрессии по определению температуры на поверхности обнаруженных звёзд с помощью нейросети и точностью прогноза RMSE <= 4500.
Описание данных:
6_class.csv — описание уже изученных звезд.
Описание признаков:
Luminosity(L/Lo)— светимость звезды относительно Солнца;Radius(R/Ro)— радиус звезды относительно радиуса Солнца;Absolute magnitude(Mv)— абсолютная звёздная величина, физическая величина, характеризующая блеск звезды;Star color— (white,red,blue,yellow,yellow-orangeи др.) — цвет звезды, который определяют на основе спектрального анализа;Star type— тип звезды (описание типов в таблице ниже);
| Тип звезды | Номер, соответствующий типу |
|---|---|
| Коричневый карлик | 0 |
| Красный карлик | 1 |
| Белый карлик | 2 |
| Звёзды главной последовательности | 3 |
| Сверхгигант | 4 |
| Гипергигант | 5 |
Temperature (K)—(Целевой признак)— абсолютная температура на поверхности звезды в Кельвинах.
Ход исследования:
Подготовка данных: загрузка и изучение общей информации из представленных датасетов.Предобработка данных: стандартизация данных и обработка явных и неявных дубликатов.Исследовательский анализ данных: изучение признаков имеющихся в датасетах, их распределение, поиск выбросов/аномалий в данных.Корреляционный анализ: изучение взимосвязей между входными признаками и целевыми, а также и между ними.Подготовка данных к обучению модели: деление данных на тестовую и тренировочную выборки, feature engineering, отбор признаков для обучения с помощьюmutual_info_regression, построение пайплайна обработки данных.Построение базовой нейронной сети: получение бызовой метрики по тестовой выборки с помощью закона Стефана-Больцмана, построение базовой нейронной сети, где определяется архитектура модели и получение метрики качества ее прогноза на тестовой выборке и анализ результатов.Улучшение нейронной сети: подбор гиперпараметров для ранее полученной нейросети, добавление регуляризации и обучения с помощью батчей, получение метрики качества ее прогноза на тестовой выборке и анализ результатов, тестируется добавление аугментированных данных для улучшения точности прогноза нейросети.Общий вывод: резюмирование полученных результатов, формулировка ключевых выводов.
Результаты работы:
Для получения базовых метрик были использованы закон Стефана-Больцмана и обучена базовая нейросеть, где была определена архитектура модели.
Метрики качества RMSE:
- Закон Стефана-Больцмана —
7646.102 - Базовая нейросеть —
~3360.929
Проанализировав прогнозы модели на тестовой выборке, сделали следующие выводы, что у модели сложности с голубыми звездами 4 и 5 типа. Для повышения точности прогноза модели были использованы следующие инструменты:
- Обучение с помощью батчей;
- Добавление регуляризации;
- Подбор гиперпараметров с помощью цикла;
- Добавление аугментированных данных в тренировочную выборку.
После добавления обучения c помощью батчей и регуляризации в модель, нам удалось улучшить метрику базовой нейросети на ~13%.
Сравнение прогноза улучшенной нейросети с фактическими значениями на тестовой выборке:
analyzis_test(y_test, best_pred)
Звезды, где нейросеть ошиблась сильнее всего:
false_predict
| temperature | luminosity | radius | abs_magnitude | star_type | star_color | |
|---|---|---|---|---|---|---|
| 102 | 23000 | 127000.00000 | 36.0000 | -5.76 | 4 | blue |
| 105 | 14245 | 231000.00000 | 42.0000 | -6.12 | 4 | blue |
| 118 | 6850 | 229000.00000 | 1467.0000 | -10.07 | 5 | red |
| 141 | 21020 | 0.00150 | 0.0112 | 11.52 | 2 | blue |
| 154 | 25070 | 14500.00000 | 5.9200 | -3.98 | 3 | blue_white |
| 156 | 26140 | 14520.00000 | 5.4900 | -3.80 | 3 | blue_white |
| 159 | 37800 | 202900.00000 | 6.8600 | -4.56 | 3 | blue |
| 162 | 12675 | 452000.00000 | 83.0000 | -5.62 | 4 | blue |
| 163 | 5752 | 245000.00000 | 97.0000 | -6.63 | 4 | blue |
| 165 | 7282 | 131000.00000 | 24.0000 | -7.22 | 4 | blue |
| 173 | 26000 | 316000.00000 | 1679.0000 | -9.10 | 5 | blue |
| 177 | 11000 | 170000.00000 | 1779.0000 | -9.90 | 5 | blue_white |
| 179 | 24490 | 248490.00000 | 1134.5000 | -8.24 | 5 | blue_white |
| 205 | 19920 | 0.00156 | 0.0142 | 11.34 | 2 | blue |
| 207 | 23092 | 0.00132 | 0.0104 | 10.18 | 2 | blue |
| 221 | 12749 | 332520.00000 | 76.0000 | -7.02 | 4 | blue |
После анализа результатов мы обнаружили, что нейросеть недостаточно хорошо справляется с звездами 4 и 5 типа и голубого / бело-голубого цвета. Поэтому было принято решение добавить аугментированных данных, на основе имеющейся тренировочной выборки. К сожалению данный метод не дал должного результата и метрика оказалась хуже, чем у модели обученной на оригинальных данных.
Итоговые результаты в сводной таблице:
pivot_table
| Model | Description | Hyperparameters | RMSE | |
|---|---|---|---|---|
| 0 | Upgrade Neural Network | Улучшенная базовая нейросеть с подобранными гиперпараметрами | {'dropout': 0.05, 'batch_size': 64} | 2911.542 |
| 1 | Neural Network Augmented | Улучшенная базовая нейросеть обученная с добавлением синтетических данных | {'dropout': 0, 'batch_size': 64} | 3235.010 |
| 2 | Baseline Neural Network | Базовая нейросеть | — | 3360.929 |
| 3 | Baseline | Прогнозирование температуры с помощью закона Стефана-Больцмана | — | 7646.102 |
По итогам работы лучшей моделью стала Upgrade Neural Network.
Выполнены все поставленные задачи работы, найден метод, который лучше прогнозирует температуру звезды с помощью нейросети, а так же достигнут порог требуемого качества прогноза, значение RMSE ниже 4500, она составляет 2911.542.